雑誌に載らない話vol260
アイシン精機は2018年10月25日、名古屋大学、徳島大学との共同プロジェクトで、音声・視線・ジェスチャーを用いて操作する自動運転車を開発したと発表した。

名古屋大学・大学院の武田一哉教授、竹内栄二朗准教授、石黒祥生特任准教授らの研究グループが、徳島大学、アイシン精機と共同し、さらに豊田中央研究所の協力により、自動運転オープンソースソフトウェア「Autoware」を利用して音声認識・顔画像認識・ジェスチャー認識を組み合わせたマルチモーダル・インタフェースで自動車を直観的に操作するシステムを開発したもの。なお、この研究は、平成28年度から始まった科学技術振興機構「産学共創プラットフォーム共同研究推進プログラム」の支援のもとで行なわれている。
今回の研究、開発のポイントは、自動運転車を操作できるマルチモーダル・インタフェースを用い、音声・視線・ジェスチャーで「タクシー運転手に指示するように」自動運転車を操作可能という点だ。そのために音声認識技術、視線・顔向き・口動作認識技術、ジェスチャー認識などの技術を採用。将来の「機械-人間」協奏の一つの在り方を示している。例えば「そこを曲がって」と指をさせば、人間の意図するところで曲がってくれるなど、コミュニケーションを取りながら操作できる自動運転車が実現しているのだ。
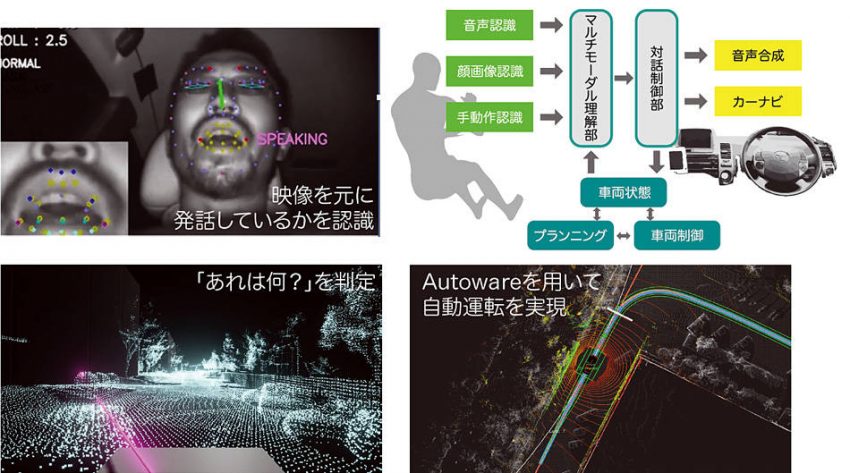
現時点では、自動運転のための周囲のセンシングや車両制御技術などは進展しているものの、実際に一般の人が自動運転車に乗り込み、目的の場所に移動するためにどのように「自動運転車を操作する」についての検討はあまり行なわれてこなかった。
自動運転車が社会に浸透し、一般の人が容易に利用できるようにするためには、自動運転車と人とのコミュニケーションが必要で、自動運転車に適したインタフェースが必要になる。この一つの理想形をタクシーに求めた。
客は運転手に行き先を告げ、必要に応じて曲がる場所などを伝え、行き先に来たら停まってもらうというやり取りは、音声による対話を中心に、ジェスチャーなどを交えながら交わされる。こうしたやり取りを、自動運転車との間で実現することを目指して研究が行なわれた。

例えば、ある建物を見ながら「あれは何?」と尋ねた時は「あれ」と言っているときにユーザが見ている建物の名称を答える必要がある。このように、各入力手段(モダリティ)の時間的関係も考慮しながら、マルチモーダル理解を行なうようになっている。
そしてその意図に応じて応答したりクルマの制御を行なうわけだ。このように、複数のモダリティを統合的に理解し、実際に自動車の制御まで行ないながら応答するマルチモーダル・インタフェースを備えた自動運転車の研究・開発は世界初となる。













